DR Solution Based on Active-Active Failover
In GreptimeDB's "Active-Active Failover" architecture, two nodes are typically deployed (for example, node A and node B):
- Both nodes provide full service capabilities to clients.
- The two nodes are peers. Neither node is a long-term fixed single primary.
- Writes use bidirectional asynchronous replication. A write accepted by either node is replicated to the peer node.
- GreptimeDB's architecture prevents circular replication.
- Queries are executed locally on each node. No cross-node query result merge is required.
The goal of this model is to provide cross-node disaster recovery with relatively low architecture complexity, without introducing a third compute node or metadata node.
Architecture and Read/Write Paths
Write path
- The client sends a write request to node A (or node B).
- The receiving node persists the write locally, then returns success to the client.
- The receiving node asynchronously replicates the write request to the peer node.
- If too many write requests remain unreplicated (threshold is configurable), the node can pause client writes to help meet RPO and RTO targets.
Query path
- Queries run locally on the node that the client connects to.
- The model does not depend on real-time query merge across two nodes.
- As long as either node is available, the query path can continue serving traffic.
- Due to the nature of async replication, we can achieve eventually consistency in this setup.
RPO and RTO
RPO
Different configurations can achieve different RPO targets.
The key configuration is the amount of reserved space for write requests pending replication.
If this space is set to 0 (bytes), asynchronous replication effectively becomes synchronous replication, and RPO is 0.
For other values, RPO can be calculated dynamically based on write size and write throughput.
RTO
RTO depends on your node failover strategy. Different failover methods and configurations can achieve different RTO targets. See "Failover Implementation Methods" below.
Failover Implementation Methods
To retain the minimality of requirements of our active-active architecture, we don't have a third node or a third service to handle the failover of GreptimeDB. Generally speaking, there are several ways to handle the failover:
- Through a LoadBalancer. If you can spare another node for deploying a LoadBalancer like the HAProxy, or if you have your own LoadBalancer service can be used, we recommend this way.
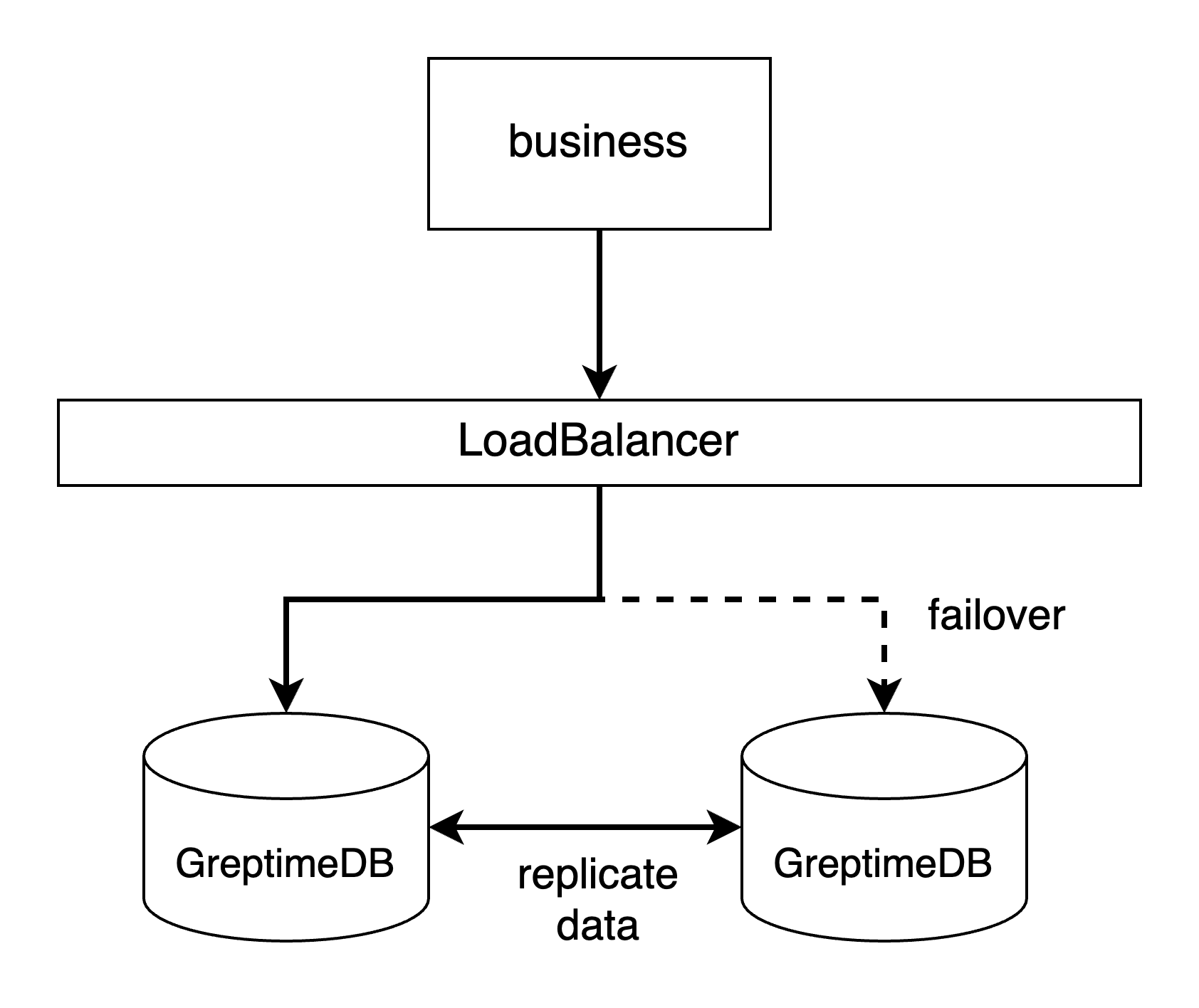
- By client SDK's failover mechanism. For example, if you are using MySQL Connector/j, you can configure the failover by setting multiple hosts and ports in the connection URL (see its document here). PostgreSQL's driver has the same mechanism. This is the most easy way to handle the failover, but not every client SDK supports this failover mechanism.
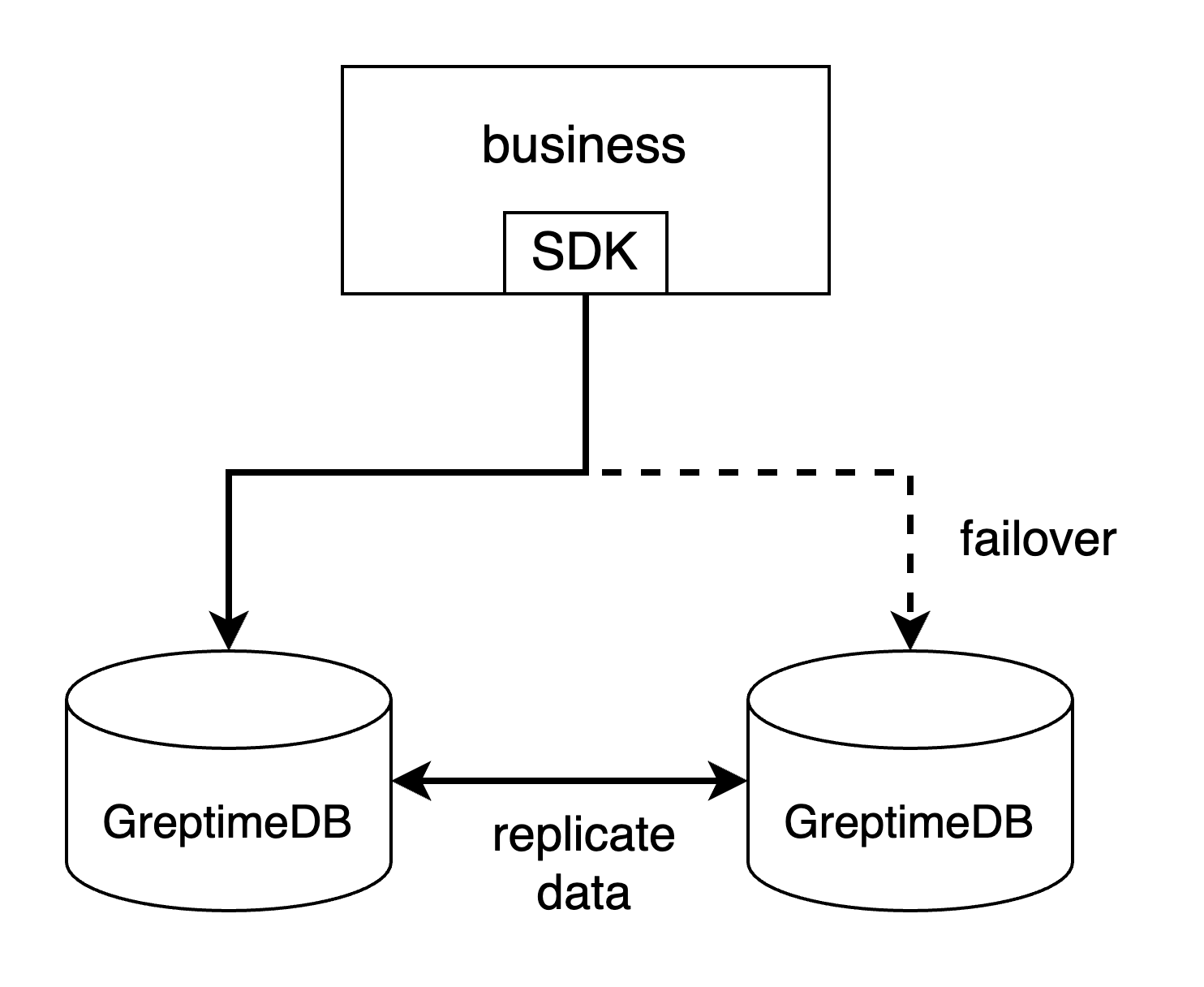
- Custom endpoint update mechanism. If you can detect the fall of nodes, you can retroactively update the GreptimeDB's endpoint set in your code.
To compare the RPO and RTO across different disaster recovery solutions, please refer to "Solution Comparison".
Summary
The core of GreptimeDB's active-active failover DR solution is:
- Two peer nodes with bidirectional asynchronous write replication.
- Local query execution on each node.
- Fast recovery from single-node failures through external failover mechanisms.
Under this model, the architecture remains simple, and both RPO and RTO targets are explicit and configurable. This disaster recovery solution could be best suited for small-to-medium size business scenarios.